AHC033バーチャル参加記
2024/06/05
トップページ次の関連記事: yukicoder No.2132 1 or X Game解説の解説
twitter pixiv yukicoder お題箱 マシュマロ
こんにちわ、$p$進大好きbot(以下、筆者)です。コンテスト参加記を書くのは初めてなので、簡単な自己紹介から。
ほぼyukicoder専の競技プログラマーですが、一応AtCoderのアカウントも持っていてたまに勉強に使わせていただいています。
使用言語は、yukicoderの難易度で★1.5以下は主にcLayでたまにpython、★2以上は主にC++です。cLayがAtCoderにないことを忘れてたまに提出時に首を傾げています。
最近yukicoderコンテストが少なめだったのでupsolveにちょうどいい問題のストックが尽きてしまったところでして、そこで長期コンテストとかやってないかなぁと思いAtCoderを調べてみたら、今現在開催中の長期コンテストはなかったので過去問一覧の長期コンテストにバーチャル参加(?)してみました。
ヒューリスティックということはスコアコンテストですね。これまでAtCoderのスコアコンテストに参加したことはなく、yukicoderなら過去25件全てのスコアコンテストを参加またはupsolveしていますが毎回さっぱりで、解説を読んでも知らないテクニックばかりなので全く勉強していませんでした。
というわけで今回は解説をある程度読んで理解することを1つの目標に頑張っていこうと思います。
問題文
問題文そのものはこちらからご確認いただけます。
大雑把に言うと、上下左右$5 \times 5$マスの広場があって、その左端にコンテナが搬入され、5台のクレーンでコンテナを運べ、右端へコンテナを置くとコンテナが搬出されます。コンテナごとに、搬出したい縦位置や搬出したい順番が決まっていて、それに従わないと罰金が入ります。また時間がかかればかかるほどお金が必要で、罰金と合わせてなるべく少ない資金でコンテナを搬出しようというものです。
クレーンは動きの自由度が高い大クレーンが1台と、自由度が低い小クレーンが4台です。クレーンにできるのは、上下左右移動と、コンテナを掴むのと、コンテナを離すのと、爆発することです。
クレーンの移動制約の1つに、他のクレーンがあるマスには移動できないというものがあるのですが、爆発したクレーンは消滅するので他のクレーンの邪魔にならないというわけです。
それでは挑戦してみましょう。
1度目の挑戦
yukicoderでスコアコンテストに挑戦する時は、
- まず自明な点を取る(得点を稼ぐための行動は何もしないが少なくとも正解ではある)提出をして、問題を理解する。
- そこから何かしら工夫をして非自明な点を取る提出をする。
という$2$段階で挑戦していますが、今回は長期コンテストのバーチャル参加なのでこれを多段階にした感じでいこうと思います。つまり最初は得点を気にせず正解することを目指して、徐々に点数を上げていこうという感じです。
というわけで最初は得点を気にせず正解を取ろうと思います。ただいつもなら本当に自明な点を狙うのですが、すると全てのクレーンを爆発させるだけになってしまいかわいそうだったので、ひとまずは左端から流れてくる各コンテナを(搬出する順番を一切気にせず)正しい上下位置で全部搬出することを目指しました。
さて、いざ実装しようと思うと難しいです。クレーンが多すぎて、筆者の実装力ではクレーン同士がぶつからないようにうまく操作できる自信がありません。
普段のコンテストであれば、必要な考察をあらかじめまとめた自作の考察ライブラリを起動するのですが、スコアコンテスト用の考察は一切登録されていないため今回は役に立ちません。
そこで代わりに、強い競技プログラマーだったらどう助言してくれるかを考えます。
イマジナリーCuriousFairy315さん「ボム抱え落ちは避けようねぇ」
というわけでまずは小クレーンを初手で全部爆発させる方針で行くボマね。大クレーン1個になれば衝突の心配もありません。あとは搬入済みのコンテナを近い順に全探索していき、それぞれ割り算を使って搬出先の上下位置を計算して運びました。
提出、そして正解! コストの合計は137917点で、延長戦順位表によると順位は750/1141位です。順位表の周りを見てみると、灰色の名前がいっぱい。筆者は黒色。ヒューリスティックコンテストに参加したことがないからですね。
灰色の人達のプロフィールを見ると、今回が初挑戦の人が多そう。同じ初挑戦同士、お互い頑張りましょう(?)
以下、マクロだらけで役に立たないと思いますがC++のソースコードの定義本体部分です。 実際の提出ページはこちらです。
IN VO Solve()
{
CIN( ll , N );
vector A( N , vector<int>() );
FOR( i , 0 , N ){
CIN_A( int , 0 , N , Ai );
A[i] = move( Ai );
}
string S{};
vector num( N , 0 );
int i = 0 , j = 0 , N_minus = N - 1;
while( true ){
while( j > 0 ){
S += "L";
j--;
}
if( num[i] == N ){
int i_up = i - 1 , i_down = i + 1;
while( i_up >= 0 && num[i_up] == N ){
i_up--;
}
while( i_down < N && num[i_down] == N ){
i_down++;
}
int direction = 0;
if( i_up == -1 ){
if( i_down == N ){
COUT( S );
REPEAT( N_minus ){
COUT( "B" );
}
} else {
direction = 1;
}
} else {
if( i_down == N ){
direction = -1;
} else {
direction = i - i_up < i_down - i ? -1 : 1;
}
}
if( direction == 0 ){
return;
} else if( direction == 1 ){
while( i < i_down ){
S += "D";
i++;
}
} else {
while( i > i_up ){
S += "U";
i--;
}
}
assert( 0 <= i && i < N && num[i] < N );
}
S += "P";
int m = A[i][num[i]++] / N;
while( i < m ){
S += "D";
i++;
}
while( i > m ){
S += "U";
i--;
}
REPEAT( N_minus ){
S += "R";
j++;
}
S += "Q";
}
}
2度目の挑戦
正解は取れましたが、これ以上はあまり得策が思いつかなかったので解説読みを解禁します。バーチャル参加とは名ばかりですね。
さすがAtCoder、解説ページにはなんと9個も解説が並んでいます。ただ動画での勉強に苦手意識があるので動画以外を読んでみました。
するとやはりいつも通り、知らない単語が出てきます。知らない単語は調べればいいのですが、漫画を読む感覚でゆるふわに勉強をしているので、まだネタバレを踏みたくないなという気持ちが打ち勝ちます。
知らない単語の意味を語感と語法だけでイメージして、どうしても調べなきゃいけないとなる時までわくわくして取っておく。この誘惑に耐えきれないものです。
というわけでいくつかの解説に出てきた「ビームサーチ」という用語を調べるのは後回し。よく聞く用語なのでイメージが捗ります。恐らくchokudaiさんが考案したものすごい遠くまで直線上に探索するアルゴリズムなんじゃないかと筆者は睨んでいます。当たるといいな。
そんなこんなでネタバレを回避しながら読んでいったら大抵の解説は分からない(自業自得)ですが、1つ分かりやすそうな解説があったので途中まで読んで参考にさせていただきました。
- rareshana (Kotori Shana), #AHC033 参加記(暫定209位), Qiita, (2024).
なるほど、コストの計算式に注目すると、次に何を目指すべきかが見えてくるわけですね。筆者は上下位置だけをまず整えたので、コストの計算式で次に重みが大きいのは搬出する順番。より正確には問題文で転倒数を用いて定義されている罰金です。
更に解説によると、転倒数を$0$にできるらしい。これはなかなか大きなヒントでした。そんなことできるんですね。この時点で色々考えてみましたが、ここではうまく証明できませんでした。
そして解説を読み進めていくと、コンテナ置き場を作るというアイデアが紹介されます。なるほど、右端以外のマスには自由にコンテナを仮置きできるというヒントが問題文にもありましたが、あらかじめ特定のマスをコンテナ置きっぱなしゾーンにしてしまうという発想はありませんでした。
コンテナ置き場を作ったら、置いてあるコンテナとぶつからないようにクレーンを動かすにはBFSが使えるとのこと。確かにそうでした、スコアコンテストでも普段通りのアルゴリズムが活躍するわけですね。学びの宝石箱でした。
これらを参考にし、早速実装してみます。コンテナ置き場は解説のマネをして、 \[ (0,2) , (0,3) , (1,2) , (1,3) , (3,2) , (3,3) , (4,2) , (4,3) \] の$8$箇所です。クレーンの移動経路も解説に習ってBFSで求めることにします。その他の基本方針は自分で考えて
- まだ搬入されていないコンテナたちに適当な点数を降る。
- 点数が低ければ低いほど、搬入すべき順番が先になるように点数を振りたい。
- 今回はコンテナ番号を$5$で割った余りに関する累積和を各行で逆順に計算して点数の定義にしてみた。
- コンテナ置き場が空いている時、左端のコンテナたちのうち点数が最も低いものを選んでコンテナ置き場に置く。
- コンテナ置き場が空いていない時、搬入済みのコンテナたちのうちコンテナ番号を$5$で割った余りが小さいものを搬出する。
という感じで試してみました。
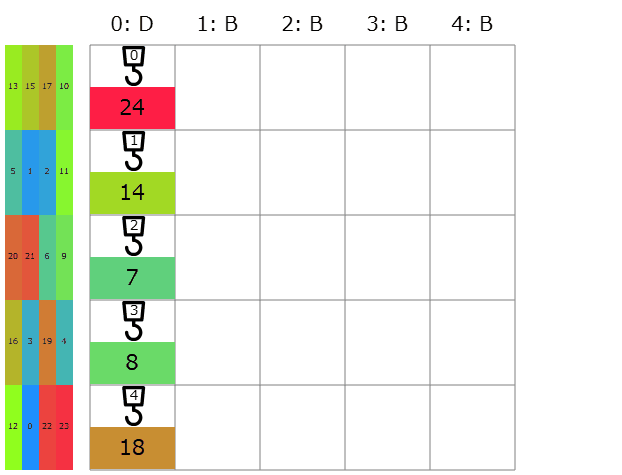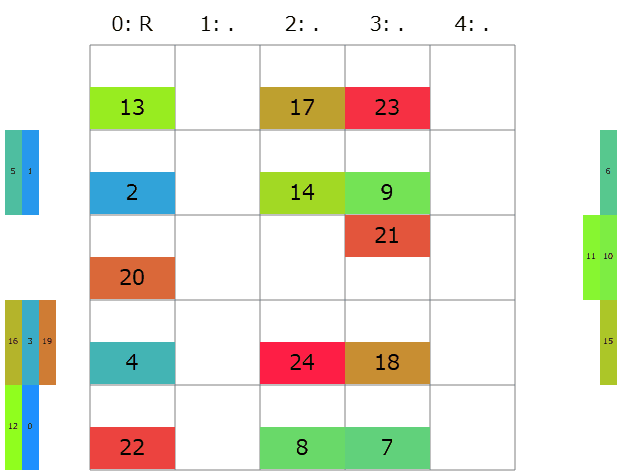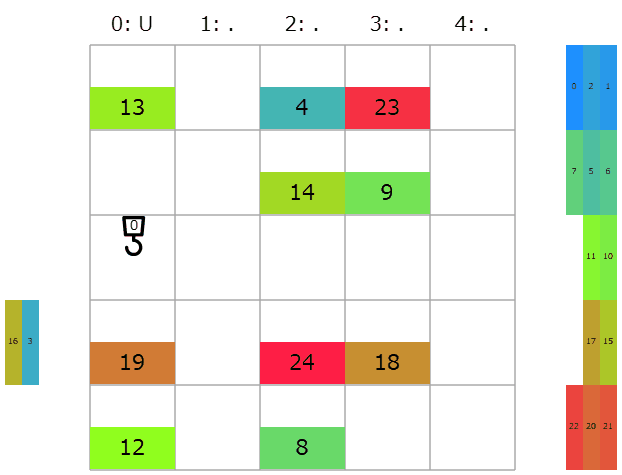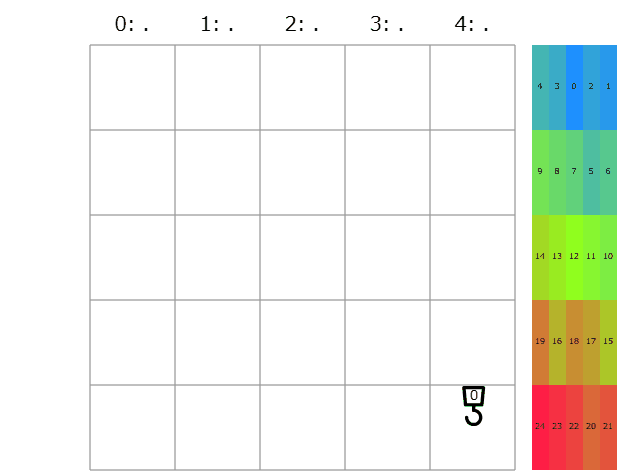
提出してみると、コストは137917→39397点と有意な減少。しかし延長戦順位表によると順位は750→726/1141位で微差。きっと他の初挑戦の人達も同じような実装をしたのかな。
以下、C++のソースコードの定義本体部分です。 実際の提出ページはこちらです。
IN VO Solve()
{
CIN( ll , N );
vector A( N , vector<int>() );
FOR( i , 0 , N ){
CIN_A( int , 0 , N , Ai );
A[i] = move( Ai );
}
auto throw_value = A;
FOR( i , 0 , N ){
FOR( j , 0 , N ){
throw_value[i][j] %= N;
}
}
auto stock_value = throw_value;
FOR( i , 0 , N ){
FOR( j , 1 , N ){
stock_value[i][j] += stock_value[i][j-1];
}
}
string S{};
T2<int> v_curr = {0,0};
auto& [i_curr,j_curr] = v_curr;
int N_minus = N - 1;
vector<T2<int>> coord_of_stock = { {0,2} , {0,3} , {1,2} , {1,3} , {3,2} , {3,3} , {4,2} , {4,3} , {0,0} , {1,0} , {2,0} , {3,0} , {4,0} };
int stock_size = coord_of_stock.size();
vector<T2<int>> item_on_stock( stock_size );
SET_HW( N , N );
grid.resize( H );
FOR( i , 0 , H ){
grid[i] = '#';
FOR( j , 1 , W ){
grid[i] += '.';
}
}
GridGraph graph{ EdgeOnGrid };
// {i,j}へデコード: EnumHW( v )
// {i,j}をコード: EnumHW_inv( { i , j } );
// 方向の文字列:direction="URDL";
// (i,j)->(k,h)の方向番号を取得: DirectionNumberOnGrid( i , j , k , h );
// v->wの方向番号を取得: DirectionNumberOnGrid( v , w );
// 方向番号の反転U<->D、R<->L: ReverseDirectionNumberOnGrid( n );
T2<int> external = {-1,-1};
BreadthFirstSearch bfs{ graph , external };
auto move_to = [&]( const int& i , const int& j ){
while( j_curr > j ){
S += 'L';
j_curr--;
}
while( j_curr < j ){
S += 'R';
j_curr++;
}
while( i_curr < i ){
S += 'D';
i_curr++;
}
while( i_curr > i ){
S += 'U';
i_curr--;
}
};
auto carry_to = [&]( const int& i , const int& j ){
assert( grid[i_curr][j_curr] == '#' );
grid[i_curr][j_curr] = '.';
bfs.Initialise( v_curr );
while( bfs.Next() != external ){}
string path{};
T2<int> v = {i,j};
while( v != v_curr ){
auto& w = bfs.prev( v );
assert( w != external );
path = direction[DirectionNumberOnGrid(w,v)] + path;
v = w;
}
S += 'P' + path + 'Q';
assert( grid[i][j] == '.' );
if( j < N_minus ){
grid[i][j] = '#';
}
if( j_curr == 0 ){
auto& num_i_curr = ++( item_on_stock[stock_size - N + i_curr].second );
if( num_i_curr < N ){
grid[i_curr][j_curr] = '#';
}
}
v_curr = {i,j};
};
auto fill_stock = [&]( const int& n ){
assert( 0 <= n && n < stock_size - N );
int value_min = 1e9 , i_opt = -1;
FOR( i , 0 , N ){
auto& num_i = item_on_stock[stock_size - N + i].second;
if( num_i < N && value_min > stock_value[i][num_i] ){
value_min = stock_value[i][num_i];
i_opt = i;
}
}
if( i_opt == -1 ){
item_on_stock[n].second = N;
return;
}
move_to( i_opt , 0 );
auto& [i_n,j_n] = coord_of_stock[n];
auto& num_i_opt = item_on_stock[stock_size - N + i_opt].second;
item_on_stock[n] = {i_opt,num_i_opt};
carry_to( i_n , j_n );
};
FOREQINV( n , stock_size - 1 , 0 ){
int i = n - ( stock_size - N );
if( i < 0 ){
fill_stock( n );
} else {
item_on_stock[n] = {i,0};
}
}
while( true ){
int value_min = 1e9 , n_opt = -1;
FOR( n , 0 , stock_size ){
auto& [i,j] = item_on_stock[n];
if( j < N && value_min > throw_value[i][j] ){
value_min = throw_value[i][j];
n_opt = n;
}
}
if( n_opt == -1 ){
break;
}
auto& v_opt = coord_of_stock[n_opt];
auto& [i_opt,j_opt] = v_opt;
move_to( i_opt , j_opt );
bfs.Initialise( v_opt );
while( bfs.Next() != external ){}
auto& [i_n,j_n] = item_on_stock[n_opt];
assert( j_n < N );
carry_to( A[i_n][j_n] / N , N_minus );
if( n_opt < stock_size - N ){
fill_stock( n_opt );
}
}
COUT( S );
REPEAT( N_minus ){
COUT( 'B' );
}
}
3度目の挑戦
まだ搬入されていないコンテナたちに割り振った点数は、転倒数を抑えることを意識したものでしたがそこまできちんと立式が考察されていないものでした。
それでもコストがだいぶ改善したということは点数の割り振りをもっと工夫すれば更にコストを抑えられるのではないでしょうか?
そこで、点数の決め方を単純な累積和ではなく、待機しているコンテナが多い行ほど優先的に搬入されるようにいい感じに$0.1$倍しつつの累積和で十進法の小数展開に翻訳してみました。これだけでどうコストが変わるでしょう?
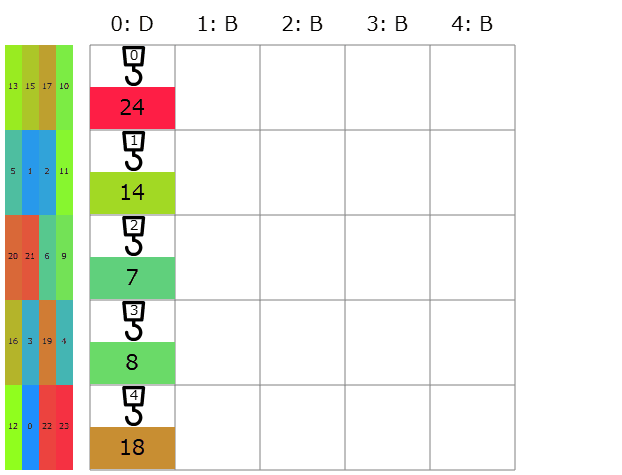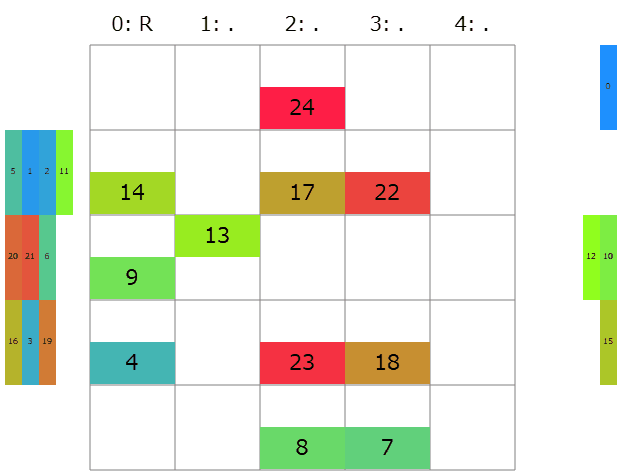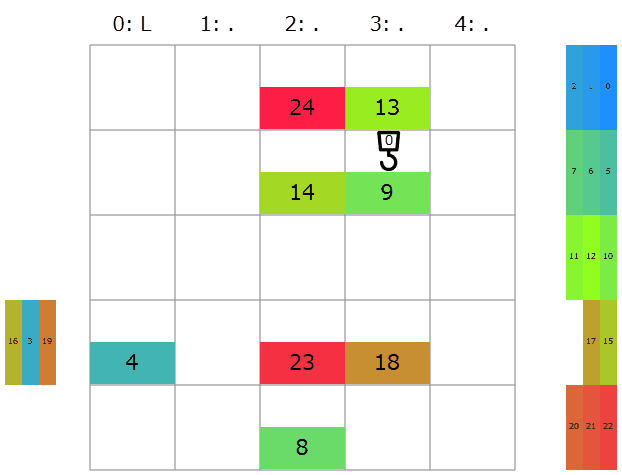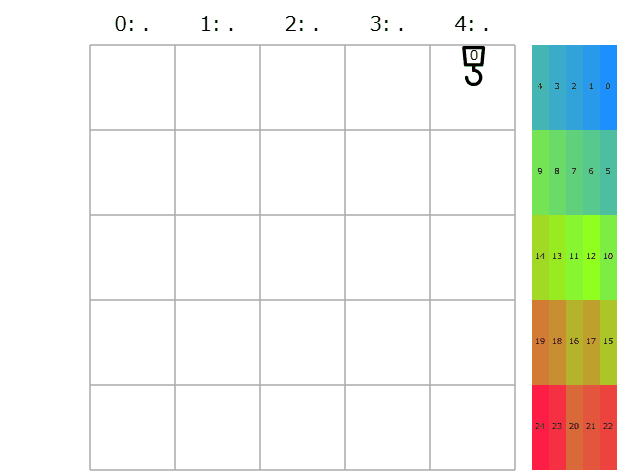
提出してみると、コストの合計は39397→43777点と悪化。よく考えたら$0.1$倍しつつの累積和は待機しているコンテナが多くても別に点数が小さくなるとは限らないですね。実際ビジュアライザを見ると、待機しているコンテナが多い行が普通に最後まで残っている様子が伺えます。正しくは、累積和を取る一番最初の項を$0.999 \cdots = 1$増やしておくなり$5$にして最大にしておくなりする必要がありました。
以下、C++のソースコードの定義本体部分です。 実際の提出ページはこちらです。
IN VO Solve()
{
CIN( ll , N );
vector A( N , vector<int>() );
FOR( i , 0 , N ){
CIN_A( int , 0 , N , Ai );
A[i] = move( Ai );
}
auto throw_value = A;
FOR( i , 0 , N ){
FOR( j , 0 , N ){
throw_value[i][j] %= N;
}
}
vector stock_value( N , vector<double>( N ) );
FOR( i , 0 , N ){
stock_value[i][N-1] = throw_value[i][N-1];
FOREQINV( j , N - 2 , 0 ){
( stock_value[i][j] = throw_value[i][j] ) += stock_value[i][j+1] * 0.1;
}
}
string S{};
T2<int> v_curr = {0,0};
auto& [i_curr,j_curr] = v_curr;
int N_minus = N - 1;
vector<T2<int>> coord_of_stock = { {0,2} , {0,3} , {1,2} , {1,3} , {3,2} , {3,3} , {4,2} , {4,3} , {0,0} , {1,0} , {2,0} , {3,0} , {4,0} };
int stock_size = coord_of_stock.size();
vector<T2<int>> item_on_stock( stock_size );
SET_HW( N , N );
grid.resize( H );
FOR( i , 0 , H ){
grid[i] = '#';
FOR( j , 1 , W ){
grid[i] += '.';
}
}
GridGraph graph{ EdgeOnGrid };
// {i,j}へデコード: EnumHW( v )
// {i,j}をコード: EnumHW_inv( { i , j } );
// 方向の文字列:direction="URDL";
// (i,j)->(k,h)の方向番号を取得: DirectionNumberOnGrid( i , j , k , h );
// v->wの方向番号を取得: DirectionNumberOnGrid( v , w );
// 方向番号の反転U<->D、R<->L: ReverseDirectionNumberOnGrid( n );
T2<int> external = {-1,-1};
BreadthFirstSearch bfs{ graph , external };
auto move_to = [&]( const int& i , const int& j ){
while( j_curr > j ){
S += 'L';
j_curr--;
}
while( j_curr < j ){
S += 'R';
j_curr++;
}
while( i_curr < i ){
S += 'D';
i_curr++;
}
while( i_curr > i ){
S += 'U';
i_curr--;
}
};
auto carry_to = [&]( const int& i , const int& j ){
assert( grid[i_curr][j_curr] == '#' );
grid[i_curr][j_curr] = '.';
bfs.Initialise( v_curr );
while( bfs.Next() != external ){}
string path{};
T2<int> v = {i,j};
while( v != v_curr ){
auto& w = bfs.prev( v );
assert( w != external );
path = direction[DirectionNumberOnGrid(w,v)] + path;
v = w;
}
S += 'P' + path + 'Q';
assert( grid[i][j] == '.' );
if( j < N_minus ){
grid[i][j] = '#';
}
if( j_curr == 0 ){
auto& num_i_curr = ++( item_on_stock[stock_size - N + i_curr].second );
if( num_i_curr < N ){
grid[i_curr][j_curr] = '#';
}
}
v_curr = {i,j};
};
auto fill_stock = [&]( const int& n ){
assert( 0 <= n && n < stock_size - N );
int value_min = 1e9 , i_opt = -1;
FOR( i , 0 , N ){
auto& num_i = item_on_stock[stock_size - N + i].second;
if( num_i < N && value_min > stock_value[i][num_i] ){
value_min = stock_value[i][num_i];
i_opt = i;
}
}
if( i_opt == -1 ){
item_on_stock[n].second = N;
return;
}
move_to( i_opt , 0 );
auto& [i_n,j_n] = coord_of_stock[n];
auto& num_i_opt = item_on_stock[stock_size - N + i_opt].second;
item_on_stock[n] = {i_opt,num_i_opt};
carry_to( i_n , j_n );
};
FOREQINV( n , stock_size - 1 , 0 ){
int i = n - ( stock_size - N );
if( i < 0 ){
fill_stock( n );
} else {
item_on_stock[n] = {i,0};
}
}
while( true ){
int value_min = 1e9 , n_opt = -1;
FOR( n , 0 , stock_size ){
auto& [i,j] = item_on_stock[n];
if( j < N && value_min > throw_value[i][j] ){
value_min = throw_value[i][j];
n_opt = n;
}
}
if( n_opt == -1 ){
break;
}
auto& v_opt = coord_of_stock[n_opt];
auto& [i_opt,j_opt] = v_opt;
move_to( i_opt , j_opt );
bfs.Initialise( v_opt );
while( bfs.Next() != external ){}
auto& [i_n,j_n] = item_on_stock[n_opt];
assert( j_n < N );
carry_to( A[i_n][j_n] / N , N_minus );
if( n_opt < stock_size - N ){
fill_stock( n_opt );
}
}
COUT( S );
REPEAT( N_minus ){
COUT( 'B' );
}
}
4度目の挑戦
というわけで点数の式を変更するだけで再提出! と思いきやここで警告文発生。
ここまで半日に1回程度のペースで息抜きにのんびり提出していたので気付きませんでしたが、なんと直前の提出から30分経たなければ次の提出をできないとのこと!
ルールはきちんと確認しなければなりませんね。yukicoderのスコアコンテストでは確か5分空けるだけで再提出できたのですが、さすが長期コンテスト。開催時間だけでなく提出間隔も長いんですね。
となるとyukicoderの時のようにちまちま実装を変えてスコアを確認する戦略が取れません。微調整は一々提出せず、抜本的な改善があった時だけ提出する感じにしましょうか。
というわけで点数の微調整以外にできることを考えてみました。1つは貪欲法。実装がめんどくさそうなので、貪欲法しか思いつかなくなったらそこで諦める感じにします。
ところでスコアコンテストにはビジュアライザという便利なものがあります。デバッグにとても役立つな~と思っていましたが、もしかしたら考察にも役立つのでは。ということで3度目の提出のビジュアライザを確認してみると、転倒数が$0$にはなっていないことを確認。
元々転倒数を$0$にする方法が思いついていなかったのでそれは当然ですが、どういう状況で転倒数が増えているかを考察してみました。
今は$5$で割った余り(以下$R$)が最も小さいものを優先的に搬出していますが、どうもこれが原因っぽい。例えば$1$行目は$R=0,1,2$のものが搬出できていて、$2$行目は$R=0$のものが搬出できている時、$1$行目に搬出すべき$R=3$のものと$2$行目に搬出すべき$R=2$のものがあれば$2$行目が優先されて搬出されます。
なるほど、搬出の優先順は$R$の小ささではなく、「まだ搬出されていないものの$R$の最小値」と$R$の差の小ささで決めるべきだったわけですね。これを修正すればコストがもっと改善されるはず!
また、待機しているコンテナがなくなった行の左端が空っぽな時、そこもコンテナ置き場にできるはずです。というわけでコンテナ置き場を途中から増やしていくようにも変更しました。
提出してみると、コストの合計は39397→25264点と2度目より改善! ただし延長戦順位表によると順位は726→699/1141位と相変わらず微増。それでも順位表の周りを見てみると、これまで灰色の名前だらけだったのが茶色の名前も増えてきました。初挑戦じゃない人達のゾーンに入ったってことですね。やる気アップです。
以下、C++のソースコードの定義本体部分です。 実際の提出ページはこちらです。
{
CIN( ll , N );
vector A( N , vector<int>() );
FOR( i , 0 , N ){
CIN_A( int , 0 , N , Ai );
A[i] = move( Ai );
}
vector<set<int>> unthrown( N );
FOR( i , 0 , N ){
FOREQ( j , 0 , N ){
unthrown[i].insert( j );
}
}
auto A_div = A;
FOR( i , 0 , N ){
FOR( j , 0 , N ){
A_div[i][j] /= N;
}
}
auto A_mod = move( A );
FOR( i , 0 , N ){
FOR( j , 0 , N ){
A_mod[i][j] %= N;
}
}
auto throw_value = A_mod;
auto set_throw_value = [&](){
FOR( i , 0 , N ){
FOR( j , 0 , N ){
throw_value[i][j] = max( A_mod[i][j] - *( unthrown[A_div[i][j]].begin() ) , 0 );
}
}
};
set_throw_value();
vector stock_value( N , vector<double>( N ) );
vector item_outside_board( N , 1 );
auto set_stock_value = [&](){
FOR( i , 0 , N ){
stock_value[i][N-1] = 5.0;
FOREQINV( j , N - 2 , 0 ){
if( item_outside_board[i] == N ){
stock_value[i][j] = 5.0;
} else {
( stock_value[i][j] = throw_value[i][j+1] ) += stock_value[i][j+1] * 0.1;
}
}
}
};
set_stock_value();
string S{};
T2<int> v_curr = {0,0};
auto& [x_curr,y_curr] = v_curr;
int N_minus = N - 1;
vector<T2<int>> coord_of_stock = { {0,2} , {0,3} , {1,2} , {1,3} , {3,2} , {3,3} , {4,2} , {4,3} , {0,0} , {1,0} , {2,0} , {3,0} , {4,0} };
int stock_size = coord_of_stock.size();
SET_HW( N , N );
grid.resize( H );
FOR( x , 0 , H ){
grid[x] = '#';
FOR( y , 1 , W ){
grid[x] += '.';
}
}
GridGraph graph{ EdgeOnGrid };
// {i,j}へデコード: EnumHW( v )
// {i,j}をコード: EnumHW_inv( { i , j } );
// 方向の文字列:direction="URDL";
// (i,j)->(k,h)の方向番号を取得: DirectionNumberOnGrid( i , j , k , h );
// v->wの方向番号を取得: DirectionNumberOnGrid( v , w );
// 方向番号の反転U<->D、R<->L: ReverseDirectionNumberOnGrid( n );
T2<int> external = {-1,-1};
BreadthFirstSearch bfs{ graph , external };
auto move_to = [&]( const int& x , const int& y ){
while( y_curr > y ){
S += 'L';
y_curr--;
}
while( y_curr < y ){
S += 'R';
y_curr++;
}
while( x_curr < x ){
S += 'D';
x_curr++;
}
while( x_curr > x ){
S += 'U';
x_curr--;
}
};
vector item_on_coord( N , vector<T2<int>>( N , {N,N} ) );
set<int> free_stock{};
auto carry_to = [&]( const int& x , const int& y ){
assert( grid[x_curr][y_curr] == '#' );
auto& [i,j] = item_on_coord[x_curr][y_curr];
assert( i != N && j != N );
grid[x_curr][y_curr] = '.';
bfs.Initialise( v_curr );
while( bfs.Next() != external ){}
string path{};
T2<int> v = {x,y};
while( v != v_curr ){
auto& w = bfs.prev( v );
assert( w != external );
path = direction[DirectionNumberOnGrid(w,v)] + path;
v = w;
}
S += 'P' + path + 'Q';
assert( grid[x][y] == '.' );
if( y < N_minus ){
auto& [i_new,j_new] = item_on_coord[x][y];
assert( i_new == N && j_new == N );
i_new = i;
j_new = j;
grid[x][y] = '#';
} else {
assert( x == A_div[i][j] );
auto itr = unthrown[x].lower_bound( A_mod[i][j] );
assert( *itr == A_mod[i][j] );
unthrown[x].erase( itr );
set_throw_value();
}
i = N;
j = N;
if( y_curr == 0 ){
if( item_outside_board[x_curr] == N ){
int n = stock_size - N + x_curr;
free_stock.insert( n );
} else {
grid[x_curr][y_curr] = '#';
i = x_curr;
j = item_outside_board[x_curr]++;
}
}
v_curr = {x,y};
};
auto fill_stock = [&]( const int& n ){
assert( 0 <= n && n < stock_size );
int value_min = 1e9 , i_opt = -1;
FOR( x , 0 , H ){
auto& [i,j] = item_on_coord[x][0];
if( i == x && value_min > stock_value[i][j] ){
value_min = stock_value[i][j];
i_opt = i;
}
}
if( i_opt == -1 ){
return;
}
move_to( i_opt , 0 );
auto& [x_n,y_n] = coord_of_stock[n];
carry_to( x_n , y_n );
};
FOREQINV( n , stock_size - 1 , 0 ){
int x = n - ( stock_size - N );
if( x < 0 ){
fill_stock( n );
free_stock.insert( n );
} else {
item_on_coord[x][0] = {x,0};
}
}
while( true ){
int value_min = 1e9 , n_opt = -1;
FOR( n , 0 , stock_size ){
auto& [x,y] = coord_of_stock[n];
auto& [i,j] = item_on_coord[x][y];
if( j < N && value_min > throw_value[i][j] ){
value_min = throw_value[i][j];
n_opt = n;
}
}
if( n_opt == -1 ){
break;
}
auto& v_opt = coord_of_stock[n_opt];
auto& [x_opt,y_opt] = v_opt;
move_to( x_opt , y_opt );
bfs.Initialise( v_opt );
while( bfs.Next() != external ){}
auto& [x,y] = coord_of_stock[n_opt];
auto& [i,j] = item_on_coord[x][y];
assert( j < N );
carry_to( A_div[i][j] , N_minus );
if( free_stock.count( n_opt ) > 0 ){
fill_stock( n_opt );
}
}
COUT( S );
REPEAT( N_minus ){
COUT( 'B' );
}
}
5度目の挑戦
恐ろしいもので長期コンテストのバーチャル参加は終わり際が見えません。貪欲法しか思いつかなくなったら終わり、と線引きはしていますが、目標も欲しいです。そこで2度目の挑戦の前に読んだ解説に書いてあったヒント「転倒数は$0$にできる」という部分を完全に理解することを目指すことにしていました。
そこで手がかりを求めて問題を読み返してみると、大クレーンの動きの制約を勘違いしていたことが判明。BFSでわざわざコンテナを避けるルートを考えなくても、コンテナを素通りできる!
そもそもBFSを採用していたのは2度目の挑戦の前に読んだ解説を参考にしたもので、そちらはイマジナリーCuriousFairy315さんと関係ないので小クレーンを爆発させていないからこそBFSが意味を持つわけです。大クレーンしか使わないのであればBFSは削除して、全探索で$\ell^1$距離最小の目的点に移動させるなどしましょう。
そして解説との設定の違いに気づくと、コンテナ置き場のサイズも$8$個に限定する意味がないことに気付きました。$8$個で嬉しいのは小クレーンが自由にコンテナを取り出せるからです。大クレーンしか動かさないのであればコンテナ置き場を最大限の$20$個にできます。
ただし、何も考えずに$20$個引き出すと、必ず転倒数が正のケースを作れてしまうことが分かりました。そこで少なくとも$1$マス余裕を持たせて$19$個まで引き出すことにしてみると、今度はどんなケースでも転倒数が$0$にできることが軽めの場合分けで確認できました!
これにて目標達成です。また序盤に$19$個引き出す際には小クレーンの衝突を気にせず運用できるため、最初に爆発させるのもやめてみます。$19$個引き出した後は大クレーンだけ動かすことにしますが、ここまで共に戦ってきた小クレーンに用済みだからと爆発を命じるのはbotの心がないbotがやることです。
小クレーンをこまめに動かして、大クレーンの妨げにならないように生存させるルートでTrue Endを目指しましょう。
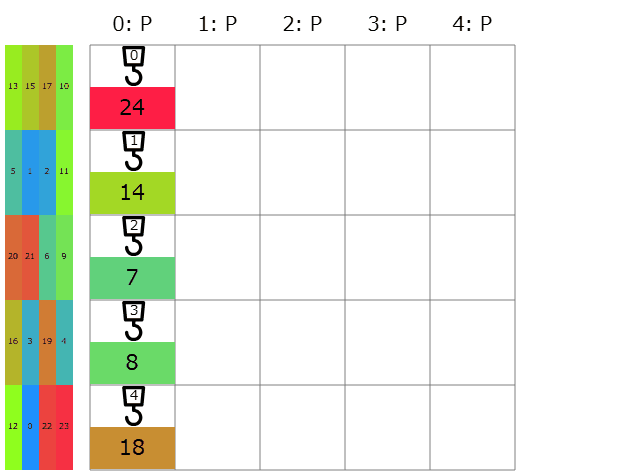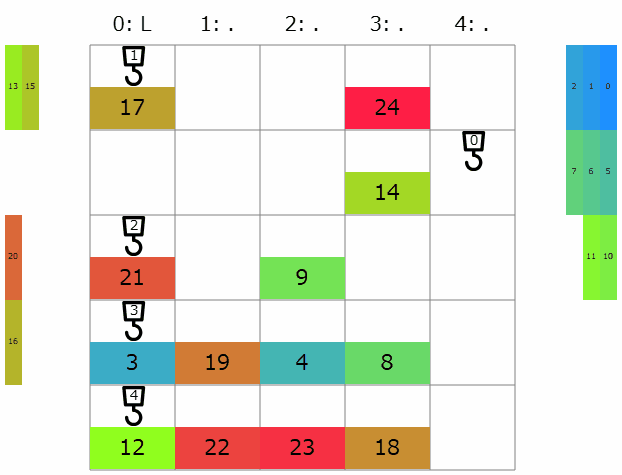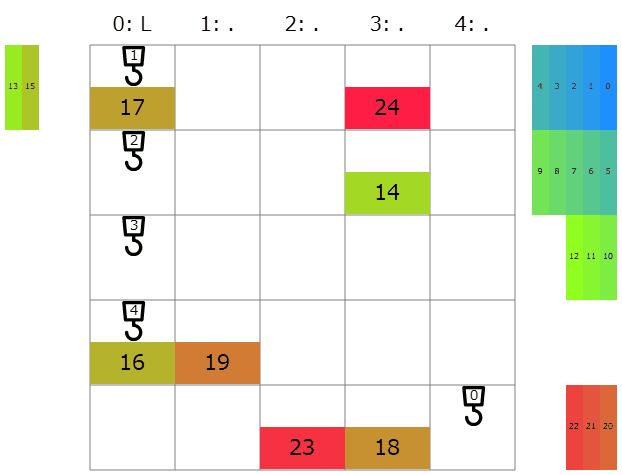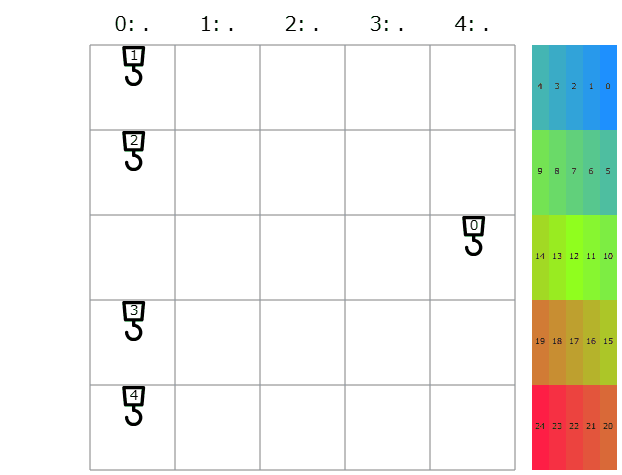
提出してみると、コストの合計は25264点→13946と更に改善! 延長戦順位表によると順位は699→423/1141位と急上昇です。これまでと違って色々な色の名前が現れて順位表もカラフル。全体の半分より上にもなれたので大満足です。
以下、C++のソースコードの定義本体部分です。 実際の提出ページはこちらです。
{
CIN( ll , N );
vector A( N , vector<int>() );
FOR( i , 0 , N ){
CIN_A( int , 0 , N , Ai );
A[i] = move( Ai );
}
vector<set<int>> unthrown( N );
FOR( i , 0 , N ){
FOREQ( j , 0 , N ){
unthrown[i].insert( j );
}
}
auto A_div = A;
FOR( i , 0 , N ){
FOR( j , 0 , N ){
A_div[i][j] /= N;
}
}
auto A_mod = move( A );
FOR( i , 0 , N ){
FOR( j , 0 , N ){
A_mod[i][j] %= N;
}
}
vector<string> S( N );
vector item_on_coord( N , vector<T2<int>>( N , {N,N} ) );
FOR( i , 0 , N ){
S[i] += "PRRRQ";
item_on_coord[i][3] = {i,0};
}
FOR( i , 0 , N ){
S[i] += "LLLPRRQ";
item_on_coord[i][2] = {i,1};
}
S[0] += "LL.RL";
FOR( i , 1 , N ){
S[i] += "LLPRQ";
item_on_coord[i][1] = {i,2};
}
vector<int> item_outside_board( N );
item_on_coord[0][0] = {0,2};
item_outside_board[0] = 3;
FOR( i , 1 , N ){
item_on_coord[i][0] = {i,3};
item_outside_board[i] = 4;
}
T2<int> v_curr = {0,0};
auto& [x_curr,y_curr] = v_curr;
int y_rest = 1;
auto move_to = [&]( const int& x , const int& y ){
while( y < y_curr ){
S[0] += 'L';
y_curr--;
bool b = y_curr == y_rest;
FOR( i , 1 , N ){
S[i] += b ? "R" : ".";
}
b ? ++y_rest : y_rest;
}
while( y_curr < y ){
S[0] += 'R';
y_curr++;
bool b = y_curr == y_rest;
FOR( i , 1 , N ){
S[i] += b ? "L" : ".";
}
b ? --y_rest : y_rest;
}
while( x_curr < x ){
S[0] += 'D';
x_curr++;
FOR( i , 1 , N ){
S[i] += x_curr == i ? "U" : ".";
}
}
while( x < x_curr ){
S[0] += 'U';
FOR( i , 1 , N ){
S[i] += x_curr == i ? "D" : ".";
}
x_curr--;
}
};
int N_minus = N - 1;
auto carry_to = [&]( const int& x , const int& y ){
auto& [i,j] = item_on_coord[x_curr][y_curr];
assert( i != N && j != N );
auto& [i_new,j_new] = item_on_coord[x][y];
assert( i_new == N && j_new == N );
if( y < N_minus ){
i_new = i;
j_new = j;
} else {
assert( x == A_div[i][j] );
auto itr = unthrown[x].begin();
assert( *itr == A_mod[i][j] );
unthrown[x].erase( itr );
}
if( y_curr == 0 && item_outside_board[x_curr] < N ){
i = x_curr;
j = item_outside_board[x_curr]++;
} else {
i = N;
j = N;
}
S[0] += 'P';
FOR( i , 1 , N ){
S[i] += ".";
}
move_to( x , y );
S[0] += 'Q';
FOR( i , 1 , N ){
S[i] += ".";
}
};
auto throw_item_on = [&]( const int& x , const int& y ){
move_to( x , y );
auto& [i,j] = item_on_coord[x][y];
assert( i != N && j != N );
carry_to( A_div[i][j] , N_minus );
};
auto L1 = [&]( const T2<int>& v1 , const T2<int>& v2 ){
return abs( v1.first - v2.first ) + abs( v1.second - v2.second );
};
auto throwable = [&]( const int& i , const int& j ){
if( i != N && j != N ){
auto itr = unthrown[A_div[i][j]].begin();
if( *itr == A_mod[i][j] ){
return true;
}
}
return false;
};
auto nearest_inside_throwable = [&](){
int d = 1e9;
T2<int> answer = {N,N};
FOR( x , 0 , N ){
FOR( y , 0 , N ){
int d_curr = L1( v_curr , {x,y} );
if( d > d_curr ){
auto& [i,j] = item_on_coord[x][y];
if( throwable( i , j ) ){
d = d_curr;
answer = {x,y};
}
}
}
}
return answer;
};
auto nearest_outside_throwable = [&](){
int answer = N;
int d = 1e9;
FOR( x , 0 , N ){
if( item_outside_board[x] < N ){
int d_curr = L1( v_curr , {x,0} );
if( d > d_curr ){
if( throwable( x , item_outside_board[x] ) ){
d = d_curr;
answer = x;
}
}
}
}
return answer;
};
auto nearest_blank = [&](){
int d = 1e9;
T2<int> answer = {N,N};
FOR( x , 0 , N ){
FOR( y , 0 , N ){
int d_curr = L1( v_curr , {x,y} );
if( d > d_curr ){
auto& [i,j] = item_on_coord[x][y];
if( i == N && j == N ){
d = d_curr;
answer = {x,y};
}
}
}
}
assert( d < N * 2 );
return answer;
};
while( true ){
auto v = nearest_inside_throwable();
auto& [x,y] = v;
if( x != N && y != N ){
throw_item_on( x , y );
} else {
int i = nearest_outside_throwable();
if( i == N ){
break;
}
move_to( i , 0 );
v = nearest_blank();
carry_to( x , y );
}
}
FOR( i , 0 , N ){
COUT( S[i] );
}
}
感想戦
初挑戦のAtCoderスコアコンテスト(ただしバーチャル参加)。とても楽しかったです。コストの計算式が分かりやすい重み付けの$1$次式なおかげで、次に何を目指せばよいかが分かりやすい。ビジュアライザがあるおかげで、時間がかかりがちなデバッグ作業もそれなりにスムーズに。そもそもビジュアライザが面白い。絵を描くのが好きなので、きっとビジュアライザを作るのも楽しいんだろうな。
その他の感想です。
- ルールと問題文の確認は重要。今回は3日間しか頑張ってませんが、もっと何日も頑張った後に初めて問題文の誤読に気づいたら悲しいですね。
- 普段の問題と同様、典型アルゴリズムをきちんと検討する。
- 思ったよりスコアコンテスト初挑戦の人が多い。yukicoderのスコアコンテストは熟練の人達が競い合っているイメージだったので参加しても最下位ら辺をうろうろしているだけでしたが、ArCoderではスコアコンテスト初挑戦の人も多いみたいなのである程度競技っぽさを味わえる。
- ゴールがないので目標を自分である程度決める。基本はスコアの計算式に出てくる変数に注目して目標を立てると良さそう。
- ビジュアライザでデバッグと考察をする。これまではビジュアライザを上級者の楽しさ共有アプリだと思っていてyukicoderのスコアコンテストでは活用していなかったので、これからは使ってみようと思います。
- デバッグといえば、何故かgdbの表示がおかしかった。長期コンテストなので実装量が多かったからいくつかのサブルーチンをラムダ式で関数化したのがいつもの実装との相違点ですが、ラムダ式内を実行中の表示が正しい行遷移にならず。もしかしてgdbはラムダ式に弱い? もしそうならば、長期コンテストはラムダ式でなく関数でサブルーチンを書いたほうが良さそう。情報求む。